X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model
Abstract
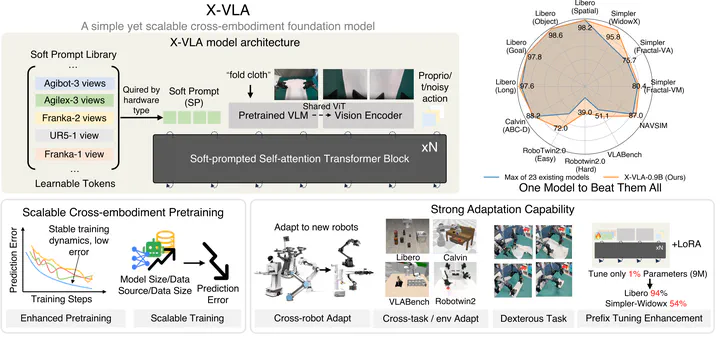
Successful generalist Vision-Language-Action (VLA) models rely on effective training across diverse robotic platforms with large-scale, cross-embodiment, heterogeneous datasets. To facilitate and leverage the heterogeneity in rich, diverse robotic data sources, we propose a novel Soft Prompt approach with minimally added parameters, by infusing prompt learning concepts into cross-embodiment robot learning and introducing separate sets of learnable embeddings for each distinct data source. These embeddings serve as embodiment-specific prompts, which in unity empower VLA models with effective exploitation of varying cross-embodiment features. Our new X-VLA, a neat flow-matching-based VLA architecture, relies exclusively on soft-prompted standard Transformer encoders, enjoying both scalability and simplicity. Evaluated across 6 simulations as well as 3 real-world robots, our 0.9B instantiation-X-VLA-0.9B simultaneously achieves SOTA performance over a sweep of benchmarks, demonstrating superior results on a wide axes of capabilities, from flexible dexterity to quick adaptation across embodiments, environments, and tasks. Website: https://thu-air-dream.github.io/X-VLA/.
Other information
- X-VLA has won First Place in the AGIBOT World Challenge (Manipulation track) @ IROS 2025!