AIR-DREAM Lab
AIR-DREAM Lab
Home
News
Researches
Publications
People
Light
Dark
Automatic
Algorithms
Dichotomous Diffusion Policy Optimization
Diffusion-based policies have gained growing popularity in solving a wide range of decision-making tasks due to their superior …
Ruiming Liang
,
Yinan Zheng
,
Kexin ZHENG
,
Tianyi Tan
,
Jianxiong Li
,
Liyuan Mao
,
Zhihao Wang
,
Guang Chen
,
Hangjun Ye
,
Jingjing Liu
,
Jinqiao Wang
,
Xianyuan Zhan
PDF
Cite
Project
Project
Discrete Diffusion for Reflective Vision-Language-Action Models in Autonomous Driving
End-to-End (E2E) solutions have emerged as a mainstream approach for autonomous driving systems, with Vision-Language-Action (VLA) …
Pengxiang Li
,
Yinan Zheng
,
Yue Wang
,
HuiminWang
,
Hang Zhao
,
Jingjing Liu
,
Xianyuan Zhan
,
Kun Zhan
,
XianPeng Lang
PDF
Cite
Project
Project
Sample Efficient Offline RL via T-Symmetry Enforced Latent State-Stitching
Offline reinforcement learning (RL) has achieved significant progress in recent years. However, most existing offline RL methods …
Peng Cheng
,
Zhihao Wu
,
Jianxiong Li
,
Ziteng He
,
Haoran Xu
,
Wei Sun
,
Youfang Lin
,
Yunxin Liu
,
Xianyuan Zhan
PDF
Cite
Project
Project
X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model
Successful generalist Vision-Language-Action (VLA) models rely on effective training across diverse robotic platforms with large-scale, …
Jinliang Zheng
,
Jianxiong Li
,
Zhihao Wang
,
Dongxiu Liu
,
Xirui Kang
,
Yuchun Feng
,
Yinan Zheng
,
Jiayin Zou
,
Yilun Chen
,
Jia Zeng
,
Ya-Qin Zhang
,
Jiangmiao Pang
,
Jingjing Liu
,
Tai Wang
,
Xianyuan Zhan
PDF
Cite
Code
Project
Project
Website
xTED: Cross-Domain Adaptation via Diffusion-Based Trajectory Editing
Reusing pre-collected data from different domains is an appealing solution for decision-making tasks, especially when data in the …
Haoyi Niu
,
Qimao Chen
,
Tenglong Liu
,
Jianxiong Li
,
Guyue Zhou
,
Yi Zhang
,
Jianming HU
,
Xianyuan Zhan
PDF
Cite
Code
Project
Project
Website
Flow Matching-Based Autonomous Driving Planning with Advanced Interactive Behavior Modeling
Modeling interactive driving behaviors in complex scenarios remains a fundamental challenge for autonomous driving planning. …
Tianyi Tan
,
Yinan Zheng
,
Ruiming Liang
,
Zexu Wang
,
Kexin ZHENG
,
Jinliang Zheng
,
Jianxiong Li
,
Xianyuan Zhan
,
Jingjing Liu
PDF
Cite
Code
Project
Project
Website
Towards Robust Zero-Shot Reinforcement Learning
The recent development of zero-shot reinforcement learning (RL) has opened a new avenue for learning pre-trained generalist policies …
Kexin ZHENG
,
Lauriane Teyssier
,
Yinan Zheng
,
Yu Luo
,
Xianyuan Zhan
PDF
Cite
Project
Website
Uni-RL: Unifying Online and Offline RL via Implicit Value Regularization
The practical implementations of reinforcement learning (RL) often face diverse settings, such as online, offline, and …
Haoran Xu
,
Liyuan Mao
,
Hui Jin
,
Weinan Zhang
,
Xianyuan Zhan
,
Amy Zhang
PDF
Cite
Code
Project
Website
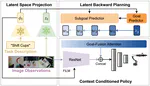
Efficient Robotic Policy Learning via Latent Space Backward Planning
Current robotic planning methods often rely on predicting multi-frame images with full pixel details. While this fine-grained approach …
Dongxiu Liu
,
Haoyi Niu
,
Zhihao Wang
,
Jinliang Zheng
,
Yinan Zheng
,
Zhonghong Ou
,
Jianming HU
,
Jianxiong Li
,
Xianyuan Zhan
PDF
Cite
Code
Project
Project
Website
Universal Actions for Enhanced Embodied Foundation Models
Training on diverse, internet-scale data is a key factor in the success of recent large foundation models. Yet, using the same recipe …
Jinliang Zheng
,
Jianxiong Li
,
Dongxiu Liu
,
Yinan Zheng
,
Zhihao Wang
,
Zhonghong Ou
,
Yu Liu
,
Jingjing Liu
,
Ya-Qin Zhang
,
Xianyuan Zhan
PDF
Cite
Code
Project
Project
Website
»
Cite
×