When Data Geometry Meets Deep Function: Generalizing Offline Reinforcement Learning
Abstract
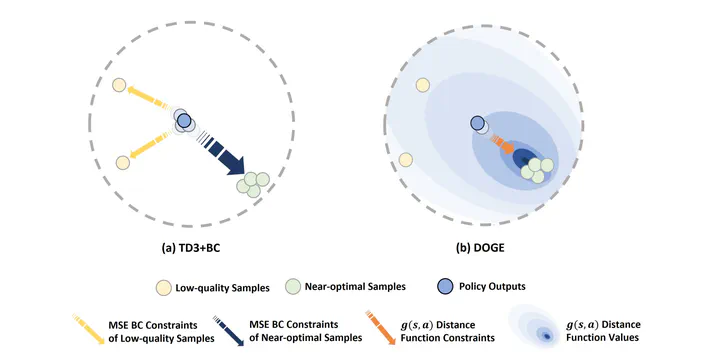
In offline reinforcement learning (RL), one detrimental issue to policy learning is the error accumulation of deep Q function in out-of-distribution (OOD) areas. Unfortunately, existing offline RL methods are often over-conservative, inevitably hurting generalization performance outside data distribution. In our study, one interesting observation is that deep Q functions approximate well inside the convex hull of training data. Inspired by this, we propose a new method, DOGE (Distance-sensitive Offline RL with better GEneralization). DOGE marries dataset geometry with deep function approximators in offline RL, and enables exploitation in generalizable OOD areas rather than strictly constraining policy within data distribution. Specifically, DOGE trains a state-conditioned distance function that can be readily plugged into standard actor-critic methods as a policy constraint. Simple yet elegant, our algorithm enjoys better generalization compared to state-of-the-art methods on D4RL benchmarks. Theoretical analysis demonstrates the superiority of our approach to existing methods that are solely based on data distribution or support constraints.