Abstract
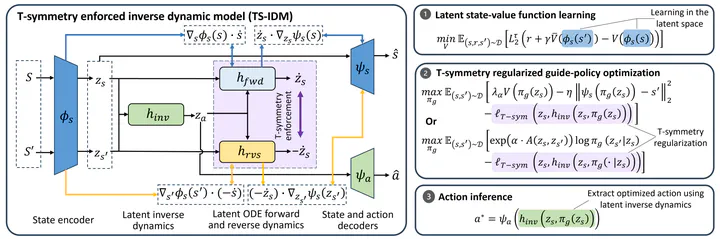
Offline reinforcement learning (RL) has achieved significant progress in recent years. However, most existing offline RL methods require a large amount of training data to achieve reasonable performance and offer limited generalizability in out-of-distribution (OOD) regions due to conservative data-related regularizations. This seriously hinders the usability of offline RL in solving many real-world applications, where the available data are often limited. In this study, we introduce a highly sample-efficient offline RL algorithm that enables state-stitching in a compact latent space regulated by the fundamental time-reversal symmetry (T-symmetry) of dynamical systems. Specifically, we introduce a T-symmetry enforced inverse dynamics model (TS-IDM) to derive well-regulated latent state representations that greatly facilitate OOD generalization. A guide-policy can then be learned entirely in the latent space to output the next state that maximizes the reward, bypassing the conservative action-level behavior constraints as adopted in most offline RL methods. Finally, the optimized action can be easily extracted by using the guide-policy’s output as the goal state in the learned TS-IDM. We call our method Offline RL via T-symmetry Enforced Latent State-Stitching (TELS). Our approach achieves amazing sample efficiency and OOD generalizability, significantly outperforming existing offline RL methods in a wide range of challenging small-sample tasks, even using as few as 1% of the data samples in D4RL datasets.